I’ve always been curious how companies like YouTube actually process and move a video from “uploaded” to “watchable in different qualities at scale”.
Instead of reading another high-level blog post, I decided to build a small but real system that does it end to end.
That’s how TCoder came to life: an event-driven, serverless video transcoding pipeline designed to mirror the real flow of large media systems, just at a smaller scale.
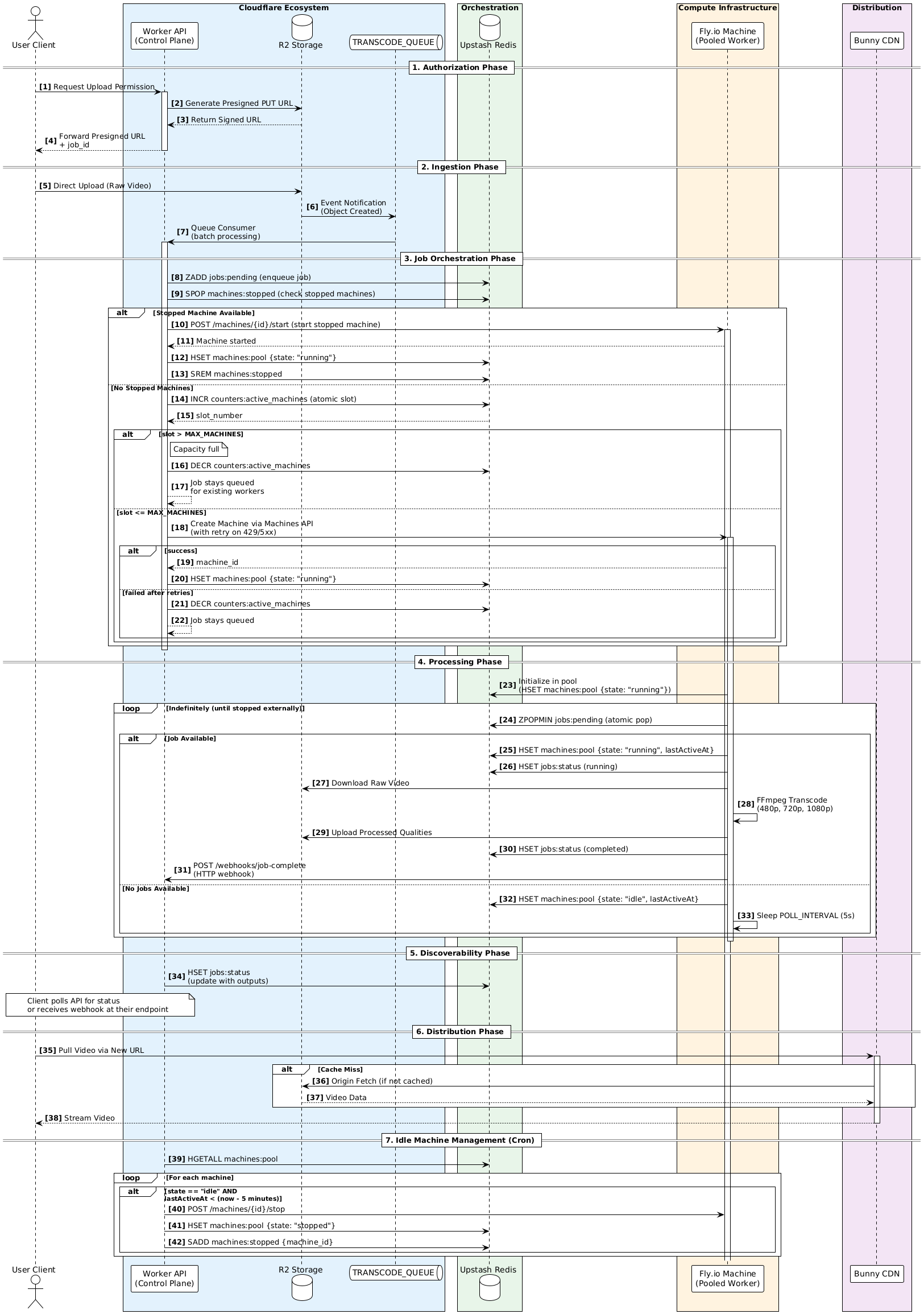
At a high level, the flow looks like this.
A client request a presigned upload link with the preset quality they want. The client uploads a video directly to object storage using a presigned URL. The storage layer emits an event when the upload completes. A control plane receives that event, enforces capacity limits, and assigns the job to a worker. Workers are ephemeral fly.io machines that run FFmpeg, upload outputs, and shut down when idle. All coordination happens through Redis. No central queue service. No long-running backend.
The stack is intentionally simple but explicit.
- Cloudflare Workers act as the control plane
- Cloudflare R2 and Queues handle ingestion and event delivery
- Upstash Redis is the state store and orchestration layer
- Fly.io Machines run pooled FFmpeg workers
- Bunny CDN distribute content to the edge with control middleware
- Bun + TypeScript everywhere for consistency
What I wanted to explore wasn’t just how to transcode a video, but how systems behave around it.
Pool-based admission control instead of spawning on every request. Reusing stopped machines to reduce cold starts and cost. Using Redis as a transparent orchestration layer for jobs, leases, and machine state. Designing workers that can run indefinitely but still be safely reclaimed.
Why Cloudflare?
I'm a long time user of Cloudflare and I picked it because it removes friction in the exact places where friction kills experiments :P
The developer experience is very coherent. Workers, R2, Queues, and Cron feel like parts of one system rather than loosely connected services glued together with configuration and IAM policies(I hate you AWS). When you’re iterating on system design, that coherence matters a lot!
Eventing on storage is also straightforward. R2 object-create events flowing directly into a Queue is exactly what an ingestion pipeline wants no custom glues needed. Upload finishes, event fires, pipeline goes.
Workers are genuinely fast to spin up. Not “Lambda cold starts are acceptable” fast, but actually fast.
Finally, Workers force statelessness. That’s a feature. It pushed me to design explicit state transitions in Redis instead of hiding behavior in memory or long-lived processes. The result is a system that’s easier to reason about, easier to inspect, and easier to break on purpose.
Cloudflare really gave me a clean, sharp control plane, and nowhere else for orchestration logic to hide.
Why Fly.io?
This part is more interesting.
I didn’t start with Fly.io. I initially tried to build this on Amazon Web Services, but it turned out to be a poor fit for this project in practice.
From my region, account setup, service access, and initial configuration took significantly longer than expected. Instead of working on system design, I found myself blocked on onboarding friction and platform-specific setup. For a learning project focused on architecture, that overhead is a big NO(I hate you AWS).
Could this have been built with Lambda, SQS, and Step Functions? Absolutely. It would have been easier. It also would have abstracted away the exact mechanics I was trying to understand.
Running FFmpeg on Lambda is possible, but painful. Packaging, execution limits, ephemeral storage constraints, cold starts, and timeouts quickly turn into an exercise in platform-specific workarounds rather than system design.
So I switched mindset to "fine, I’ll do it myself".
Fly.io gave me full control over a real machine lifecycle without managing servers. I could boot a VM, run FFmpeg, poll Redis indefinitely, and shut the machine down when idle. It’s not serverless, but it is elastic infrastructure, which is kinda much closer to how large media systems actually behave.
The key idea was treating machines as ephemeral workers! Not pets and not cattle, but something in between. They exist when needed, stopped when idle, and are reused aggressively to avoid cold starts.
Redis became the coordination layer, not because it’s better than managed queues, but because it makes the system explicit. Job queues, leases, pool membership, and machine state are all visible, inspectable, and debuggable(Yes for that).
Tradeoffs
Yes, this is more complex than a fully managed pipeline. Yes, Redis is doing work a managed queue could do. Yes, I had to design admission control and idle cleanup.
But it was fun :P
This is a learning project to understand how real media pipelines behave under load, failure, and scaling constraints. The full architecture, state model, and tradeoffs are documented in the README.
Full Arch:
Repo: https://github.com/v0id-user/tcoder Demo Site: https://tcoder-web.cloudflare-c49.workers.dev/